I remember the first time I asked a smart speaker to play my favorite song. There was a pause, a soft chime, and then the melody filled the room. It felt like magic, a seamless interaction that transcended mere technology. But how does this magic work? How does a cylindrical device sitting on my countertop interpret my casual speech, understand my intent, and then execute a command, all in a matter of seconds? This isn't just about voice recognition; it's a symphony of hardware, advanced algorithms, and cloud computing that transforms mere sound waves into actionable intelligence.
**The Invisible Orchestra: From Sound Waves to Digital Signals**
Before any AI can 'understand' us, our smart speakers first need to 'hear' us. This is far more complex than a simple microphone picking up sound. Imagine a bustling household: the TV is on, kids are playing, maybe even the washing machine is humming in the background. Your smart speaker needs to isolate your voice from this cacophony.
**Advanced Microphones and Beamforming**
The first crucial step lies in the hardware. Most smart speakers aren't equipped with just one microphone; they boast an array of them, typically between four and eight. These microphone arrays are strategically placed to capture sound from all directions. Think of it like a human ear, but with superpowers, capable of distinguishing subtle directional differences in sound.
This is where **beamforming** comes into play. Beamforming is a signal processing technique that allows the speaker to focus its "listening" on a particular direction. By analyzing the tiny time delays in when a sound wave reaches each microphone, the device can calculate the sound's origin. It then enhances the audio coming from that specific direction while suppressing sounds from other directions. This is why you can often speak to your smart speaker from across the room, even with background noise, and it still picks up your command. You can learn more about how microphones capture sound on [Wikipedia](https://en.wikipedia.org/wiki/Microphone).
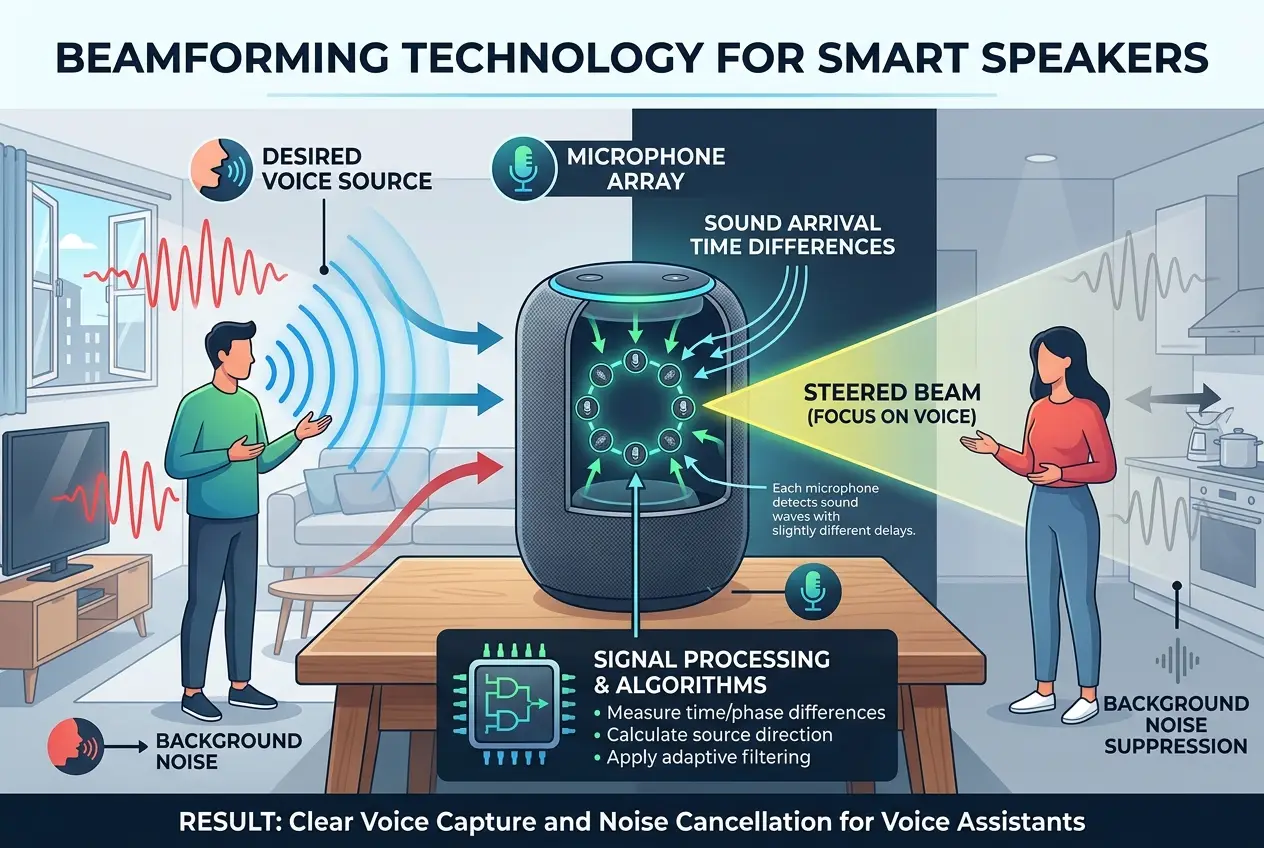
**Noise Cancellation: Silencing the Clutter**
Even with beamforming, ambient noise remains a challenge. Modern smart speakers employ sophisticated **digital signal processing (DSP)** techniques for noise cancellation. These algorithms identify repetitive or static background noises (like an air conditioner or refrigerator hum) and filter them out. Dynamic noise, like a sudden laugh or a door creak, is harder to eliminate entirely but can be significantly reduced. This combination of beamforming and DSP ensures a cleaner, clearer audio input for the next stage. It’s a similar principle to what allows premium noise-canceling headphones to silence your world, as discussed in our blog on /blogs/how-do-noise-canceling-headphones-silence-your-world-6215.
**The Wake Word: Your Digital Assistant's Ear Opener**
Before your smart speaker begins processing your full command, it's constantly listening for a "wake word" – "Alexa," "Hey Google," "Siri," etc. This is a highly specialized, always-on recognition model that runs locally on the device, consuming minimal power.
When the device detects the wake word, it "wakes up" and starts recording your subsequent speech. This local processing is critical for privacy, as it means the device isn't constantly sending everything it hears to the cloud. Only after the wake word is detected and verified does the recorded audio snippet, containing your command, get transmitted.
**From Sound to Text: Speech-to-Text (STT) Engines**
Once your voice command, isolated and cleaned, leaves the smart speaker and travels to the cloud, the real magic of AI begins. This is where the raw audio is transformed into written text that computers can understand.
**Acoustic Models and Phonemes**
The journey starts with **acoustic models**. These models are trained on vast datasets of human speech, linking specific sounds (phonemes) to their written representations. When your audio arrives, the STT engine breaks it down into tiny segments, identifying phonemes like the 'k' sound in "cat" or the 'ah' sound in "father." It then tries to match these phonemes to sequences of words. This process is complex because speech isn't always clear-cut; people speak with different accents, paces, and intonations.
**Language Models and Context**
After identifying potential phonemes, the system uses **language models**. These are statistical models that predict the likelihood of certain word sequences appearing together. For example, if the acoustic model detects sounds that could be "recognize" or "wreck a nice," the language model knows that "recognize speech" is far more probable than "wreck a nice beach" in the context of a voice assistant. This statistical prediction helps correct errors from the acoustic model and ensures accuracy. The field of speech recognition has evolved dramatically, as detailed on [Wikipedia's Speech Recognition page](https://en.wikipedia.org/wiki/Speech_recognition).
**Deep Learning's Role**
Modern STT engines heavily rely on **deep neural networks**. These networks can learn incredibly complex patterns and nuances in speech, improving accuracy significantly over older methods. They are trained on millions of hours of transcribed audio, allowing them to adapt to different speakers, accents, and speaking styles. This is a core component of how AI is able to process and understand human language, akin to the advancements being made in decoding animal languages, which we explored in /blogs/can-ai-decode-animal-language-new-rosetta-stone-5105.
**Understanding the Intent: Natural Language Processing (NLP)**
Now that your voice command is in text format, the smart speaker's cloud-based AI needs to figure out what you *mean*. This is the domain of **Natural Language Processing (NLP)**.
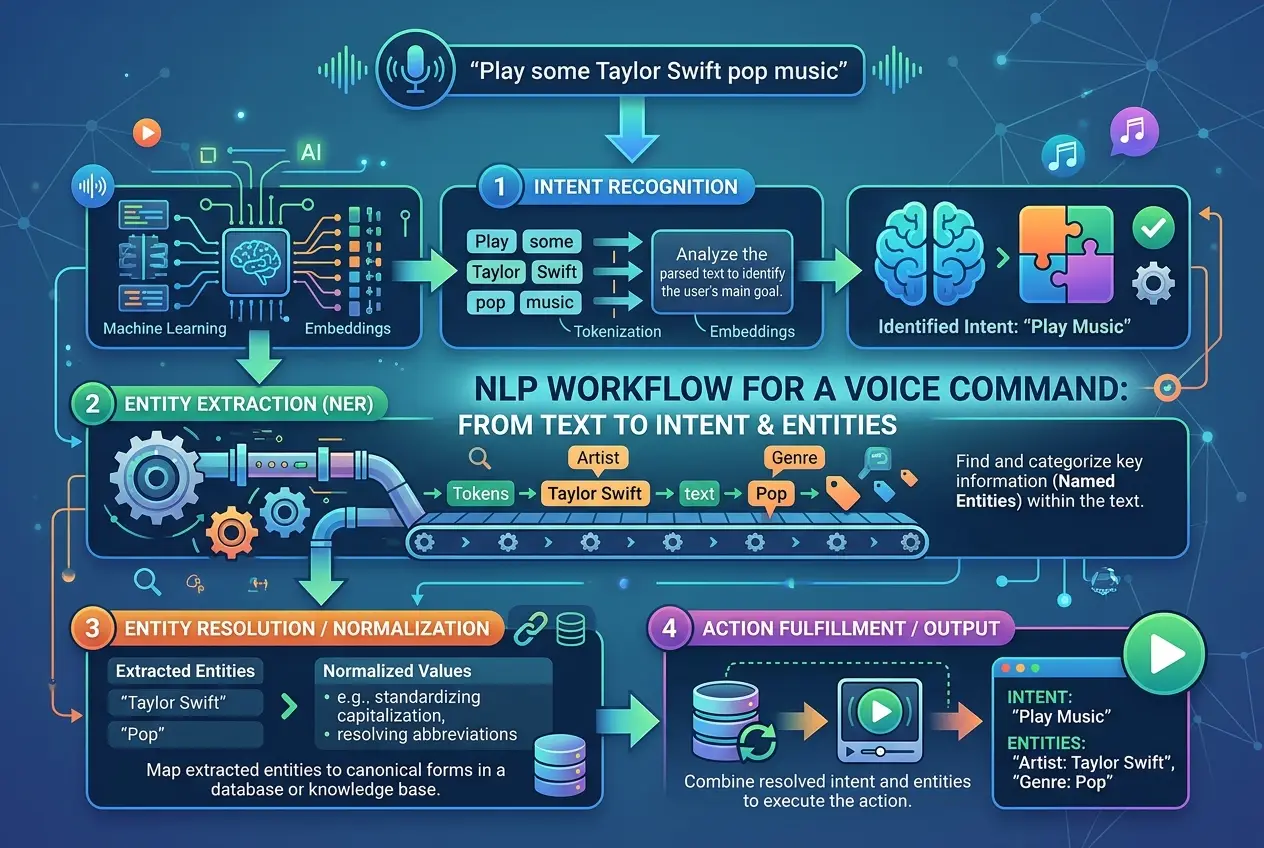
**Parsing and Semantic Analysis**
NLP takes the transcribed text and breaks it down, identifying key elements. It performs **parsing** to understand the grammatical structure of the sentence (e.g., subject, verb, object). Then comes **semantic analysis**, which delves into the meaning of the words and phrases.
Consider the command: "Play the new song by Taylor Swift."
* **Intent:** The system identifies the user's intent as "play music."
* **Entities:** It extracts crucial pieces of information, or "entities," such as "new song" (descriptor) and "Taylor Swift" (artist).
This allows the system to differentiate between "set a timer for ten minutes" and "what time is it in ten minutes," even though both contain similar keywords. The nuances of human language, including synonyms, sarcasm, and slang, make NLP a continuously evolving challenge.
**Context and Personalization**
The best smart speakers also leverage context. If you say "Play that again," the AI remembers the previous command. If you frequently listen to a specific genre, the system might prioritize that in ambiguous requests. Over time, these systems even learn your individual speech patterns and preferences, making interactions smoother and more personalized.
**Executing the Command: Cloud Services and Integration**
Finally, once the intent and entities are understood, the AI needs to act.
**API Integration**
Smart speakers don't have built-in music libraries or weather sensors. Instead, they rely on **Application Programming Interfaces (APIs)** to connect with various online services. When you ask for music, the AI sends a request via an API to a music streaming service (like Spotify or Apple Music). When you ask for the weather, it queries a weather service API. This distributed architecture allows smart speakers to access an almost limitless range of information and functionalities without needing to store everything locally. This reliance on vast, interconnected networks mirrors the complexity we discussed in /blogs/is-the-internet-gaining-a-collective-mind-9582.
**Feedback Loop and Learning**
Every interaction with your smart speaker is a learning opportunity for the AI. When a command is successfully executed, the system reinforces its understanding. When there's a misunderstanding, that data helps train future models, making the system smarter and more accurate over time. This continuous learning, often through vast data aggregation, is a hallmark of modern AI development, enhancing its ability to handle unforeseen scenarios.
**The Future of Voice AI**
The journey of a voice command from your lips to your smart speaker’s action is a testament to incredible technological convergence. From the precision engineering of microphone arrays and sophisticated digital signal processing to the complex dance of acoustic and language models powered by deep learning, it's a field constantly pushing boundaries. As these systems become more intuitive and context-aware, I believe we'll see voice interfaces move beyond simple commands to truly anticipatory and intelligent interactions, further blurring the lines between human intention and digital response. The future holds even more seamless integration, with voice AI potentially understanding emotional cues and engaging in more natural, multi-turn conversations, evolving from assistants to genuine companions.
Frequently Asked Questions
Smart speakers use advanced beamforming and voice separation techniques. While beamforming focuses on the primary speaker, some high-end models can even identify and separate individual voices using machine learning, allowing them to understand commands even in group conversations, though this is still an active area of research.
No, smart speakers are not always recording and sending everything to the cloud. They continuously listen for a specific 'wake word' (e.g., 'Alexa,' 'Hey Google') using local processing. Only after detecting and verifying this wake word is your subsequent speech recorded and sent to cloud servers for processing. This design is crucial for privacy and efficiency.
Yes, modern smart speakers are trained on massive datasets of speech from diverse populations, allowing them to understand a wide range of accents within supported languages. They also support multiple languages, often allowing users to switch between them or even use a mix in some contexts, thanks to advanced linguistic models and continuous learning.
If the internet connection is lost, most smart speaker functionalities will be severely limited. While the wake word detection might still work locally, the device cannot send audio to the cloud for speech-to-text conversion or natural language processing, nor can it access external services like music streaming or weather updates. Some very basic functions, like setting a timer, might still operate locally depending on the device.
Smart speakers employ several privacy measures. As mentioned, recording only starts after a wake word. The audio sent to the cloud is anonymized and encrypted. Users typically have control over their voice recordings, able to review and delete them through their account settings. Companies are also subject to data protection regulations, though ongoing discussions about data usage and privacy are always important. You can find more details on data privacy regulations on [Wikipedia's GDPR page](https://en.wikipedia.org/wiki/General_Data_Protection_Regulation).
Verified Expert
Alex Rivers
A professional researcher since age twelve, I delve into mysteries and ignite curiosity by presenting an array of compelling possibilities. I will heighten your curiosity, but by the end, you will possess profound knowledge.
Leave a Reply
Comments (0)
No approved comments yet. Be the first to share your thoughts!
 Join Us
Join Us



 Alex Rivers
Alex Rivers



































Leave a Reply
Comments (0)